图片识别 (Image Recognition)
Published by dugufeng
language:chineseexamplevisionmultimodalqwen-vl
图片识别 (Image Recognition)
Author: dugufeng
Tags: language:chinese, example, vision, multimodal, qwen-vl
Dify Version: v1.9.2+(请填写你测试通过的 Dify 版本)
一个简单的多模态工作流,输入一张图片,使用 Qwen-VL 模型返回对图片的中文描述。
✨ 核心特性
- 支持多模态图像输入,自动生成中文描述。
- 基于 Qwen2.5-VL-32B-Instruct 模型,具备强大的视觉理解能力。
- 无需额外工具配置,开箱即用。
🚀 如何使用
- 设置 API 密钥:
- 此工作流依赖
langgenius/siliconflow供应商。 - 请确保你已在 Dify 的“凭据”中为 SiliconFlow (或相关供应商) 设置了有效的 API 密钥。
- 此工作流依赖
- 配置工具:
- 无需配置额外工具。
- 运行工作流:
- 在“开始”节点的
imageUrl变量中上传一张图片。 - 运行工作流,并在“结束”节点查看
text输出(即图片描述)。
- 在“开始”节点的
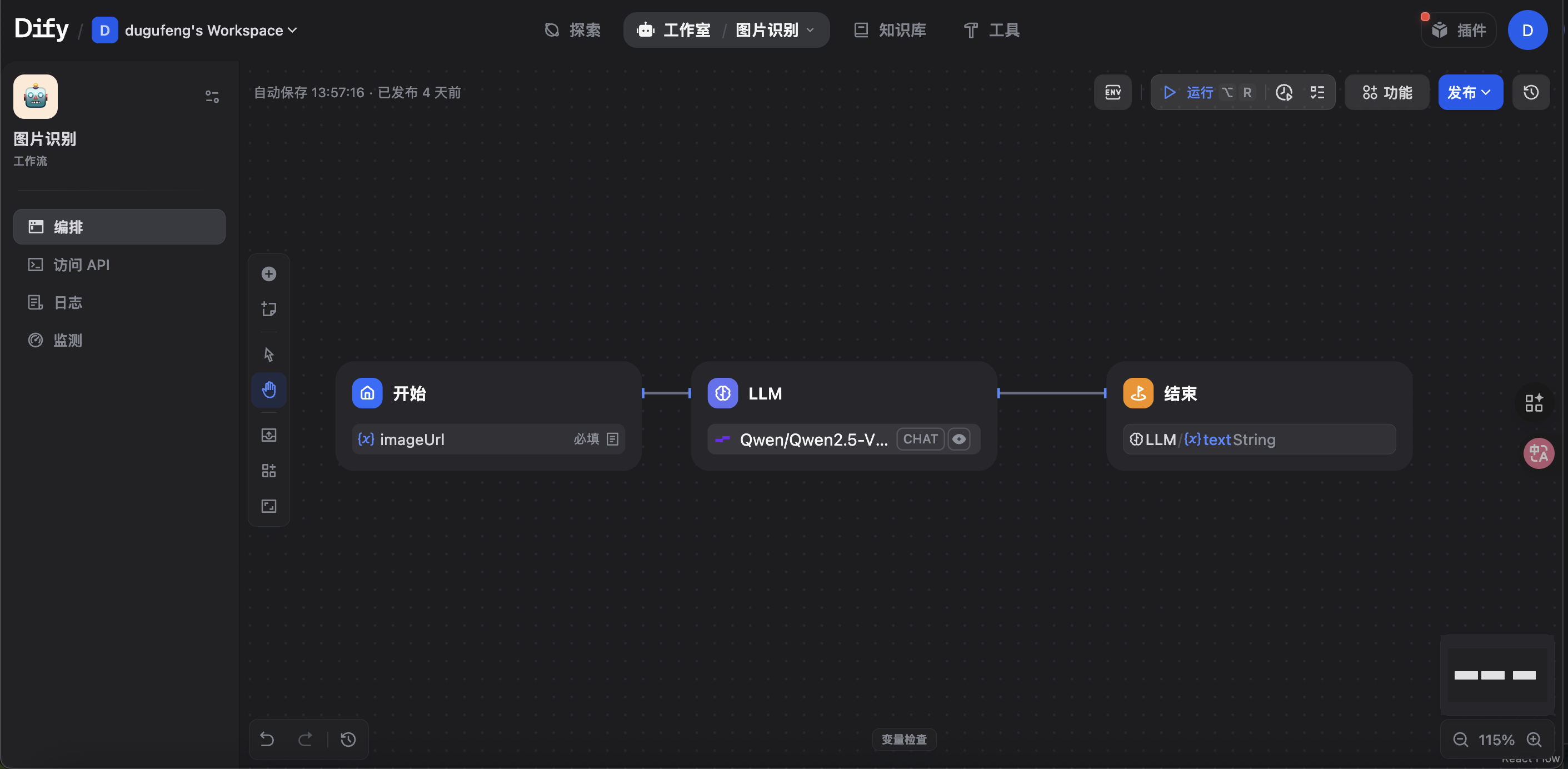
🛠️ 工作流节点
- 开始节点: 接收一个
file(文件) 类型的输入,变量名为imageUrl。 - LLM 节点:
- 使用
Qwen/Qwen2.5-VL-32B-Instruct多模态模型。 - 开启了“视觉 (vision)”功能,并将
imageUrl变量传入。 - Prompt (中文): "提取图片核心信息,用简洁准确的语言输出图片内容描述..."
- 使用
- 结束节点: 返回一个
text(字符串) 类型的输出,即 LLM 生成的描述。
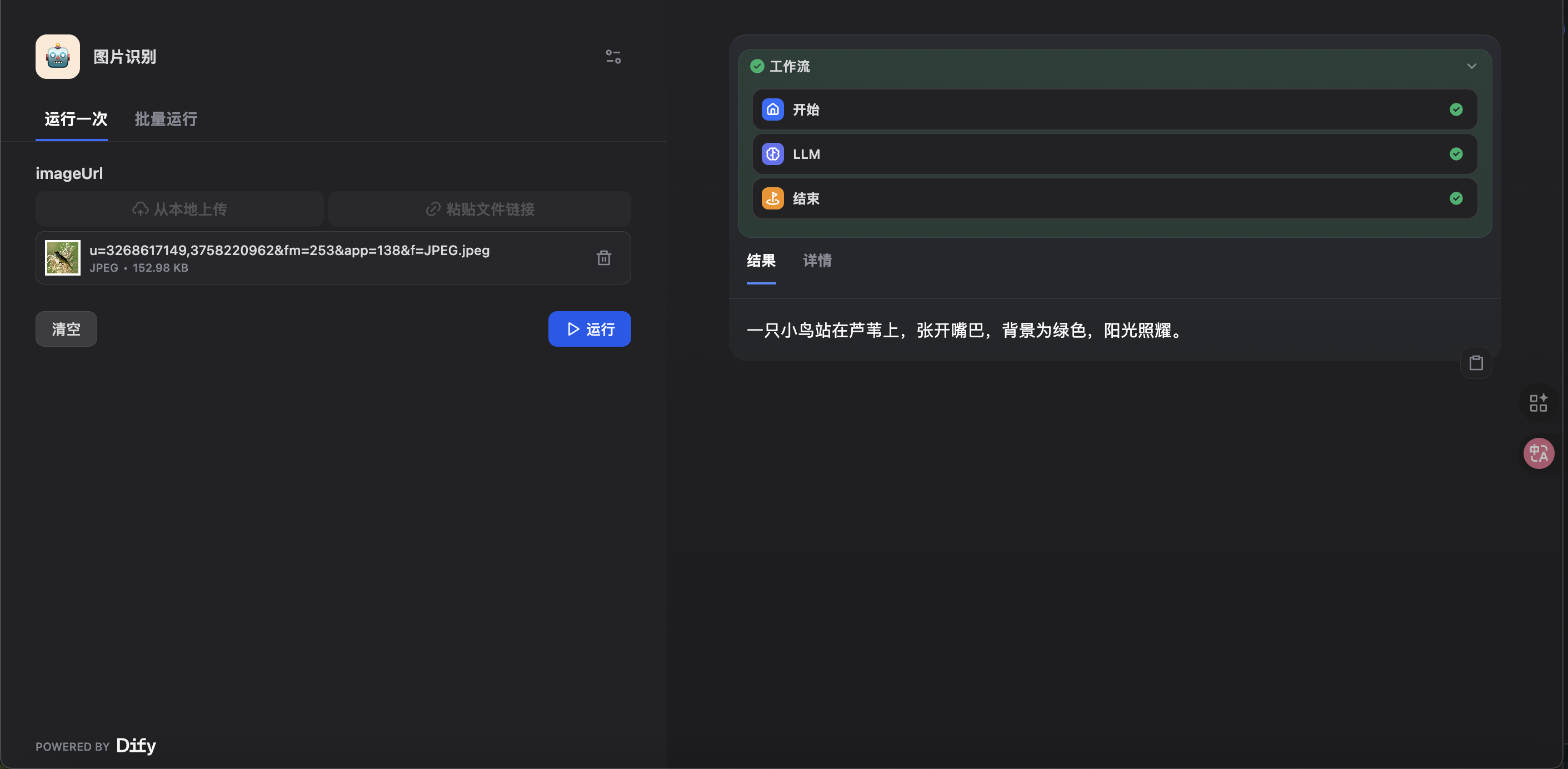
📸 运行截图 (强烈推荐)
工作流图
运行示例
Details
Likes0
Copies0
Languagelanguage:chinese
Dify Versionv1.9.2+
Published2025-10-30
Models Used
Qwen/Qwen2.5-VL-32B-Instruct
DU
dugufeng
Workflow Author
GitHub Path
vision/image-recognition-cn