Image Recognition (English)
Published by dugufeng
language:englishvisionmultimodalqwen-vlsiliconflow
Image Recognition (English)
Author: dugufeng
Tags: language:english, vision, multimodal, qwen-vl, siliconflow
This is a straightforward multimodal workflow. It receives an uploaded image and uses the Qwen2.5-VL-32B-Instruct model to return a concise description of the image in English.
🛠️ 关键元数据 (Technical Details)
- Dify Version:
v1.9.0+(Please fill in the Dify version you have tested)
🚀 关键前置条件 (Pre-conditions)
1. SiliconFlow API Key:
- This workflow relies on the
langgenius/siliconflowprovider. - Please ensure you have configured a valid API Key for SiliconFlow in your Dify "Credentials".
🚀 如何使用
- Set API Keys:
- Ensure your SiliconFlow API Key is correctly set up in Dify's "Credentials".
- Configure Tools:
- No other tools need configuration.
- Run the Workflow:
- In the "Start" node's
imageUrlvariable, upload an image (or provide a URL). - Run the workflow and check the "End" node for the
textoutput (the image description).
- In the "Start" node's
🛠️ 工作流节点 (Optional)
- Start Node: Receives a
filetype input namedimageUrl. - LLM (Vision) Node:
- Uses
Qwen/Qwen2.5-VL-32B-Instructmodel withvisionenabled. - Receives the
imageUrlas context. - Uses an English System Prompt (see above) to generate a concise description.
- Uses
- End Node: Outputs the final
text(string) description.
📸 运行截图 (Highly Recommended)
工作流图

运行示例
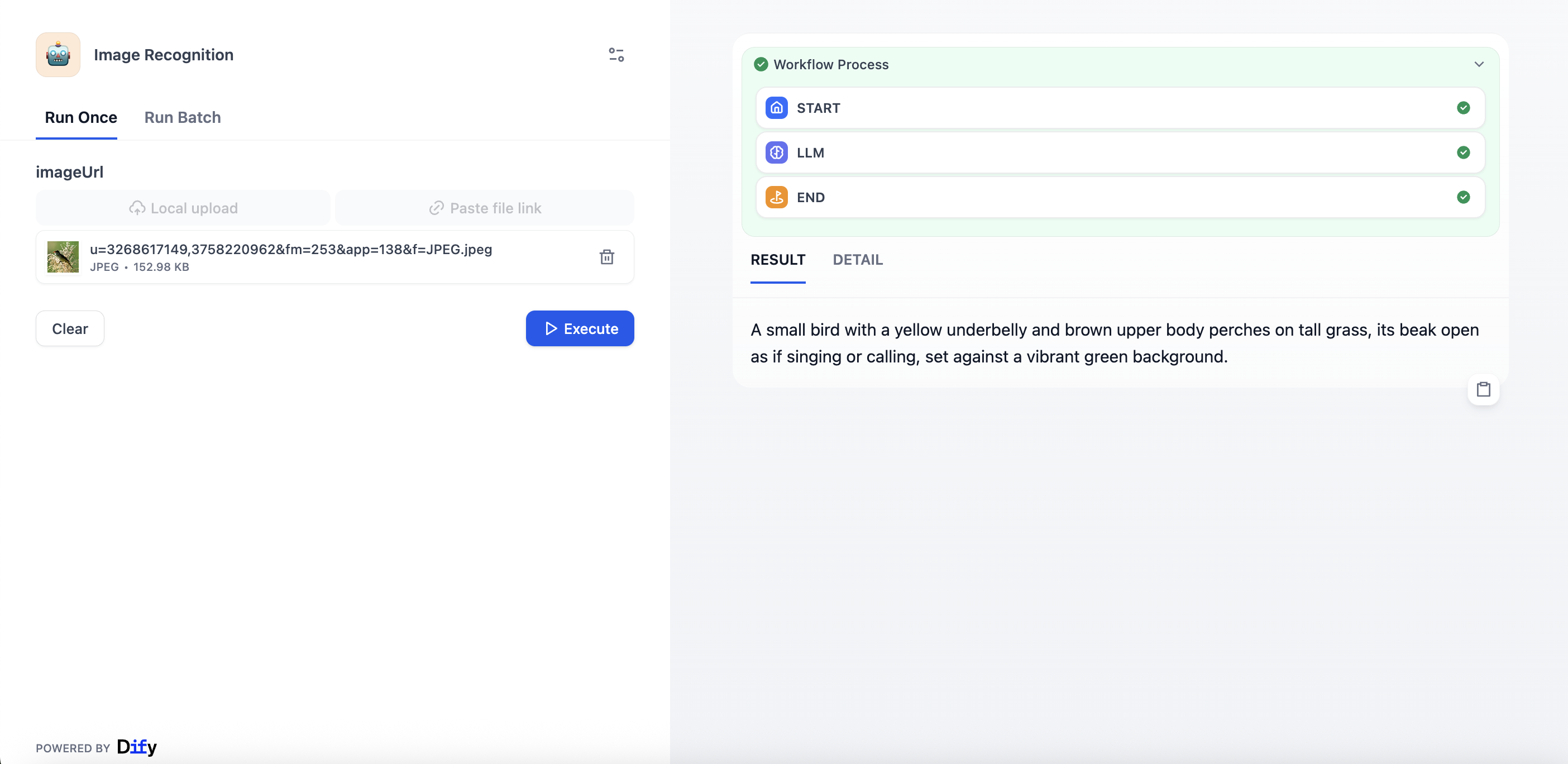
Details
Likes0
Copies0
Languagelanguage:english
Dify Versionv1.9.0+
Published2025-10-30
Models Used
Qwen/Qwen2.5-VL-32B-Instruct
DU
dugufeng
Workflow Author
GitHub Path
vision/image-recognition-en